📌 Whisper(ウィスパー)完全ガイド【2026年最新版】
💡 ツール概要
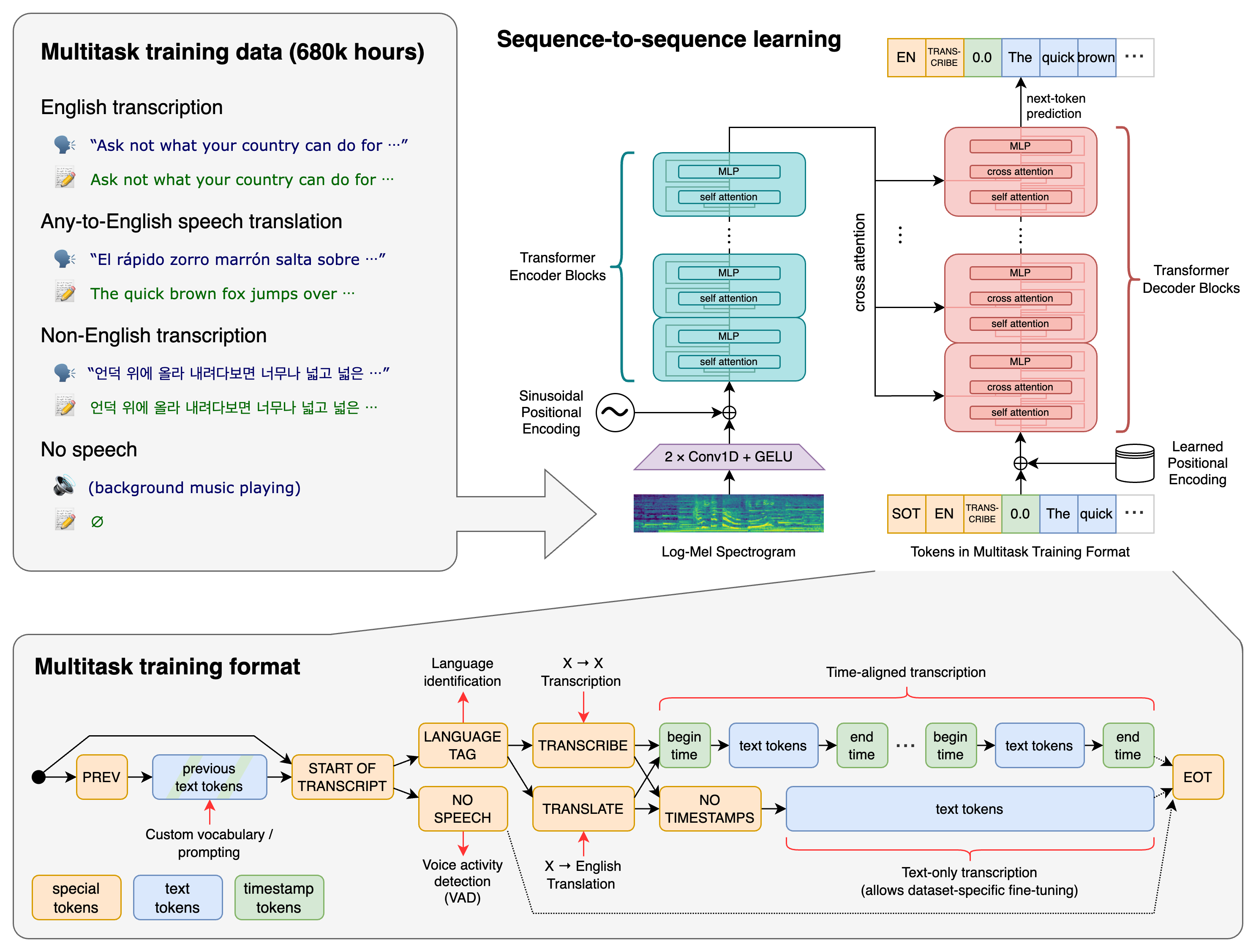
Whisperは、2022年9月にOpenAIがリリースしたオープンソースの自動音声認識(ASR)システムです。68万時間以上のマルチリンガルかつマルチタスクの教師付きデータで学習されており、99言語の音声認識と英語への翻訳に対応しています。その最大の特徴は、アクセント、背景ノイズ、専門用語に対する高い堅牢性です。従来の音声認識システムが苦手としていた多様な音声環境でも安定した精度を発揮します。2024年10月にはWhisper Large V3 Turboがリリースされ、アーキテクチャの最適化によりデコーダー層を32から4に削減、5.4倍の速度向上を実現しました。2025年3月にはgpt-4o-transcribeモデルが登場し、Whisperをさらに超える精度を達成していますが、Whisperはオープンソースかつローカル実行可能という点で引き続き広く利用されています。完全にローカルで動作可能なため、音声データを外部サーバーに送信する必要がなく、プライバシーが完全に保護されます。医療分野では3万人以上の臨床医と40以上の医療システムでWhisperベースのツールが活用されており、エンタープライズから個人開発者まで幅広い層に支持されています。
#このツールは、AI技術の急速な進化の中で独自のポジションを確立しており、2025年以降もアクティブなアップデートと機能拡張が継続されている。ユーザーベースの拡大と共に、コミュニティからのフィードバックを取り入れた改善が進められている点も評価できる。
⚙️ 主要機能の詳細解説

多言語音声認識(Automatic Speech Recognition)
99言語に対応した音声からテキストへの変換機能です。英語、スペイン語、フランス語などの高リソース言語では3〜8%の平均ワードエラーレート(WER)を達成しています。日本語を含むアジア言語にも対応しており、実用的な精度で音声認識が可能です。
翻訳機能
多言語の音声を英語テキストに翻訳する機能を内蔵しています。音声認識と翻訳を同時に行えるため、多言語コンテンツの英語化に便利です。
モデルサイズの選択肢
tiny(39M)、base(74M)、small(244M)、medium(769M)、large-v3(1.55B)、large-v3-turbo(809M)と複数のモデルサイズが用意されており、デバイスの性能と精度のトレードオフに応じて最適なモデルを選択できます。
Whisper Large V3 Turbo
2024年10月にリリースされた最新モデルで、Large V3と比較して5.4倍の処理速度を実現しながら、精度の低下は最小限に抑えられています。デコーダー層を32から4に削減するアーキテクチャ最適化により、リアルタイムに近い処理が可能になりました。
ローカル実行
完全にオフラインで動作可能なため、インターネット接続不要で音声認識を行えます。機密性の高い音声データの処理や、ネットワーク環境が不安定な場所での利用に最適です。
OpenAI API経由の利用
ローカル実行だけでなく、OpenAIのAPIを通じてクラウドベースの音声認識も利用可能です。API経由では1分あたり0.006ドルという低コストで、高精度な文字起こしサービスにアクセスできます。25MBのファイルサイズ制限があり、それ以上のファイルはチャンキングが必要です。
💰 料金プラン完全ガイド
オープンソース版(完全無料)
GitHub上で公開されているオープンソースモデルは完全に無料で利用できます。ローカル環境にインストールすることで、処理回数や時間の制限なく音声認識を行えます。ただし、GPUを搭載したコンピュータが推奨され、GPU環境の準備にはコストがかかる場合があります。
OpenAI API(従量課金 / 1分あたり0.006ドル)
OpenAIのAPI経由でWhisperモデルを利用する場合は、1分あたり0.006ドルの従量課金制です。1時間の音声ファイルの文字起こしでわずか0.36ドルという非常にリーズナブルな価格設定です。25MBのファイルサイズ制限があります。
gpt-4o-transcribe(API / 1分あたり0.006ドル)
2025年3月にリリースされた新しい音声認識モデルで、Whisperよりさらに高い精度を実現しています。API価格はWhisperと同等です。OpenAIはこちらのモデルの使用を推奨しています。
🌏 日本語対応の実態
Whisperは99言語に対応しており、日本語の音声認識にも対応しています。日本語はWhisperの学習データに含まれる言語の一つで、一般的な日本語音声に対して実用的な精度で文字起こしが可能です。ただし、英語やスペイン語などの高リソース言語と比較すると精度にはやや差があり、専門用語や方言、早口の音声では認識精度が低下する場合があります。日本語の句読点の自動挿入や文節の区切りについても、完璧ではないため後処理が必要なケースがあります。Large V3モデルでは前バージョンと比較して学習データが635%増加しており(68万時間から500万時間以上)、日本語を含む各言語の精度が向上しています。医療用語や法律用語など専門的な日本語に対してはファインチューニングが推奨されます。UIは提供されていないため、コマンドラインやAPIでの利用が基本であり、日本語のUIや公式ドキュメントはありません。ただし、多数の日本語チュートリアルやラッパーツールが公開されています。
#日本語での利用を検討する際は、無料版やトライアル期間中に自社の具体的なユースケースで日本語対応の品質を確認することを強く推奨する。
✅ メリット5つ
1. オープンソースで完全無料のローカル実行
MITライセンスで公開されており、商用利用を含めて完全に無料で利用できます。ローカルで動作するため、音声データが外部に送信されることがなく、プライバシーが完全に保護されます。
2. 99言語対応の圧倒的な多言語サポート
99言語に対応しており、単一のモデルで世界中のほぼすべての主要言語の音声認識が可能です。多言語環境での利用において他に類を見ない汎用性を持ちます。
3. ノイズ・アクセントに対する高い堅牢性
68万時間以上の多様な音声データで学習されているため、アクセント、背景ノイズ、専門用語に対して従来の音声認識システムよりはるかに堅牢です。実環境での利用に強い設計です。
4. API利用時の圧倒的な低コスト
1分あたり0.006ドル(1時間で0.36ドル)という価格は、商用音声認識サービスの中で最も安価な部類に入ります。大量の音声データを処理する場合のコストパフォーマンスは圧倒的です。
5. 豊富なエコシステムとコミュニティ
オープンソースであるため、Whisperを基盤とした多数のツール、ラッパー、統合が世界中の開発者によって構築されています。Hugging Face、PyTorch、各種フレームワークとの連携も充実しています。
#
上記のメリットに加え、定期的なアップデートによる機能改善と、ユーザーコミュニティからのフィードバックを反映した継続的な品質向上も大きな利点である。カスタマーサポートの対応品質も高く、導入後の運用フェーズでもスムーズなサポートが期待できる。
✅ デメリット3つ
1. リアルタイム処理のネイティブサポートなし
Whisperはバッチ処理向けに設計されており、ネイティブのリアルタイム音声認識機能は持っていません。リアルタイム処理にはサードパーティの実装やストリーミングラッパーが必要です。
2. 技術的な知識が必要
GUIは提供されておらず、コマンドラインやPythonスクリプトでの操作が基本です。インストール、モデル選択、GPU設定など技術的な知識が必要で、非技術者には敷居が高いです。
3. AIハルシネーション(幻覚)の問題
無音部分や背景ノイズのみの区間で、存在しない発話を「幻覚」として生成してしまうことがあります。特に医療分野では誤った文字起こしが患者の安全に関わるため、必ず人間による確認が必要です。
💡 具体的な活用事例・ユースケース5つ
1. 医療分野での診察記録
3万人以上の臨床医がWhisperベースのツールを使用して診察記録の文字起こしを行っています。医師が患者との会話に集中しながら、自動的にカルテが生成される効率的なワークフローが実現されています。
2. ポッドキャスト・動画の文字起こし
ポッドキャストエピソードやYouTube動画の文字起こしに広く活用されています。多言語対応により、グローバルなコンテンツの字幕生成やトランスクリプト作成が低コストで行えます。
3. 議事録の自動生成
企業内の会議やオンラインミーティングの音声を文字起こしし、議事録を自動生成。APIの低コストにより、大量の会議データを経済的に処理できます。
4. 学術研究のインタビュー分析
研究者が収集したインタビュー音声データを一括で文字起こし。ローカル実行により研究対象者のプライバシーを保護しながら、大量の質的データを効率的にテキスト化できます。
5. 多言語コンテンツのローカライゼーション
99言語の音声認識と英語翻訳を組み合わせ、多言語のメディアコンテンツを英語テキストに変換。字幕制作やコンテンツ翻訳のワークフローの起点として活用されています。
🚀 始め方ステップバイステップ
1. Python環境を準備: Python 3.8以上がインストールされていることを確認します。
2. Whisperをインストール: `pip install -U openai-whisper` コマンドでインストールします。
3. ffmpegをインストール: 音声ファイル処理に必要なffmpegをインストールします。
4. モデルを選択: tiny/base/small/medium/large-v3/large-v3-turboから用途に合ったモデルを選びます。
5. 文字起こしを実行: `whisper audio.mp3 --model medium --language ja` でコマンドを実行します。
6. 結果を確認: テキスト、SRT、VTTなどの形式で出力結果を確認します。
7. API利用(代替): ローカル環境が用意できない場合はOpenAIのAPIを利用します。
#
導入後は、最初の1〜2週間を「学習期間」として設定し、様々な機能を試しながらツールの特性を把握することを推奨する。この期間に得た知見を基に、自社の業務フローへの組み込み方を設計すると、本格運用への移行がスムーズになる。チームでの利用を検討している場合は、まず1〜2名のパイロットユーザーが先行して利用を開始し、ベストプラクティスを確立した後にチーム全体に展開するアプローチが効果的である。
💡 活用のコツ・裏技
- ▸モデルサイズの適切な選択: 精度を重視するならlarge-v3、速度重視ならlarge-v3-turbo、リソース制約があればmediumがバランス良好です
- ▸言語指定で精度向上: `--language ja` で日本語を明示的に指定すると、言語の自動検出による誤認識を防げます
- ▸VAD(音声活動検出)の活用: Silero VADを使用した前処理でWhisperに渡す前に無音区間を除去すると、ハルシネーションを大幅に削減できます
- ▸チャンキングで大容量ファイル対応: API利用時の25MB制限は、pydubなどのライブラリでファイルを分割することで対応できます
- ▸GPU活用で処理速度を大幅向上: NVIDIA GPUをCUDA経由で使用すると、CPU処理と比較して10倍以上の速度向上が見込めます
- ▸gpt-4o-transcribeの検討: 最高精度を求める場合は、WhisperではなくOpenAI APIのgpt-4o-mini-transcribeモデルの使用を検討しましょう
#
- ▸初めて利用する際は、簡単なタスクから始めて徐々に複雑なユースケースに進むことで、ツールの特性と限界を効率的に把握できる。公式のチュートリアルやヘルプドキュメントを事前に確認しておくと、学習曲線を大幅に短縮できる。
- ▸定期的に新機能やアップデート情報をチェックし、最新の機能を活用する習慣をつける。AIツールは進化が速いため、数ヶ月前の使い方が最適でなくなっている場合がある。
🎯 向いている人・向いていない人
向いている人
- ▸音声認識をアプリケーションに組み込みたい開発者。オープンソースで自由にカスタマイズ・統合できます
- ▸プライバシーを重視する組織。完全ローカル処理でデータが外部に出ません
- ▸大量の音声データを低コストで処理したいユーザー。API利用時のコストパフォーマンスは圧倒的です
- ▸多言語コンテンツを扱う企業。99言語対応は他に類を見ません
- ▸AIや機械学習の研究者。オープンソースモデルのファインチューニングや実験に最適です
向いていない人
- ▸プログラミング知識のない一般ユーザー。GUIがなくコマンドラインでの操作が必要です
- ▸リアルタイムの音声認識が必要な人。ネイティブのストリーミング対応がありません
- ▸GPUを持たないユーザー。CPU処理は非常に遅く、実用的ではない場合があります
- ▸すぐに使える完成品ツールを求める人。環境構築やパラメータ調整が必要です
📊 総合評価とまとめ
Whisperは、OpenAIが世界に贈ったオープンソース音声認識のゲームチェンジャーです。99言語対応、高いノイズ堅牢性、完全ローカル実行可能という特性は、2026年現在でも他の追随を許さない独自の価値を持っています。APIの1分0.006ドルという低コストは、商用音声認識サービスのコスト構造を根本から変えました。gpt-4o-transcribeの登場により最高精度のポジションは譲りましたが、オープンソースとしてのカスタマイズ性、プライバシー保護、コストフリーのローカル実行は引き続き強力なアドバンテージです。技術的な知識が求められるため万人向けではありませんが、開発者、研究者、プライバシーを重視する組織にとっては最も価値のある音声認識ソリューションの一つです。ハルシネーションの問題には注意が必要ですが、適切な前処理と後処理を組み合わせることで十分に実用的な精度が得られます。
⚖️ 競合ツールとの比較
Whisper vs Google Cloud Speech-to-Text
Google Cloud STTは商用グレードの音声認識サービスで、リアルタイムストリーミングに対応し、125以上の言語をサポートしています。Whisperは完全にオープンソースでローカル実行可能という独自の強みがあり、データを外部に送信したくない場合にはWhisperが唯一の選択肢です。コストの面でも、大量処理の場合はローカル実行のWhisperが最も経済的です。リアルタイム処理とサポート付きのサービスならGoogle、コストとプライバシー重視ならWhisperです。
Whisper vs AssemblyAI
AssemblyAIは文字起こし、話者分離、センチメント分析、要約などの高度な機能をAPIで提供する商用プラットフォームです。Whisperは基本的な文字起こしと翻訳に特化しており、高度な後処理機能は自前で構築する必要があります。すぐに使える高機能APIならAssemblyAI、カスタマイズ性とコスト重視ならWhisperです。
Whisper vs Deepgram
Deepgramは高速なリアルタイム音声認識と低レイテンシーに強みを持つ商用サービスです。WhisperにはネイティブのリアルタイムサポートがなくStrming対応にはサードパーティの実装が必要です。リアルタイム音声認識ならDeepgram、バッチ処理とオープンソースの自由度ならWhisperです。
📌 最新アップデート情報(2026年)
2026年のWhisper周辺では、OpenAIからgpt-4o-transcribeおよびgpt-4o-mini-transcribeモデルが提供されており、API経由ではWhisperを超える精度が利用可能になっています。OpenAIはWhisper APIよりもgpt-4o-mini-transcribeの使用を推奨していますが、APIの料金はWhisperと同等の1分0.006ドルです。オープンソースのWhisperモデル自体には2026年初頭時点で大きなアップデートはありませんが、コミュニティによるファインチューニングモデルやストリーミング対応ラッパーは継続的に進化しています。Faster Whisperなどの高速実装も改善が続いており、GPUなしでもある程度実用的な速度で動作するようになっています。Hugging Faceでのダウンロード数は累計で数千万回を超え、世界で最も利用されているオープンソース音声認識モデルとしての地位を確立しています。
📌 よくある質問(FAQ)
Q: Whisperを使うにはプログラミング知識が必要ですか?
A: はい、基本的にPythonとコマンドラインの操作知識が必要です。ただし、Whisperを内部で使用するGUIツール(MacWhisperやWhisper.cppなど)も多数公開されており、プログラミング知識なしで利用できるサードパーティツールもあります。
Q: GPUがなくてもWhisperは動きますか?
A: CPU上でも動作しますが、処理速度が非常に遅くなります。1時間の音声ファイルの処理にGPUなら数分で済むところ、CPUでは数時間かかる場合があります。tinyやbaseモデルならCPUでも比較的実用的な速度で動作します。
Q: WhisperとOpenAI APIのどちらを使うべきですか?
A: プライバシーを重視する場合や大量処理でコストを削減したい場合はローカル実行のWhisper、手軽さや最新モデルの品質を求める場合はOpenAI API(gpt-4o-mini-transcribe推奨)が適しています。API利用は1分0.006ドルと非常に低コストです。
Q: Whisperのハルシネーション問題とは何ですか?
A: 無音部分や背景ノイズのみの区間で、存在しない発話テキストを生成してしまう現象です。医療分野などでは重大な問題になる可能性があるため、VAD(音声活動検出)による前処理と人間によるレビューが推奨されます。