

💡 ツール概要
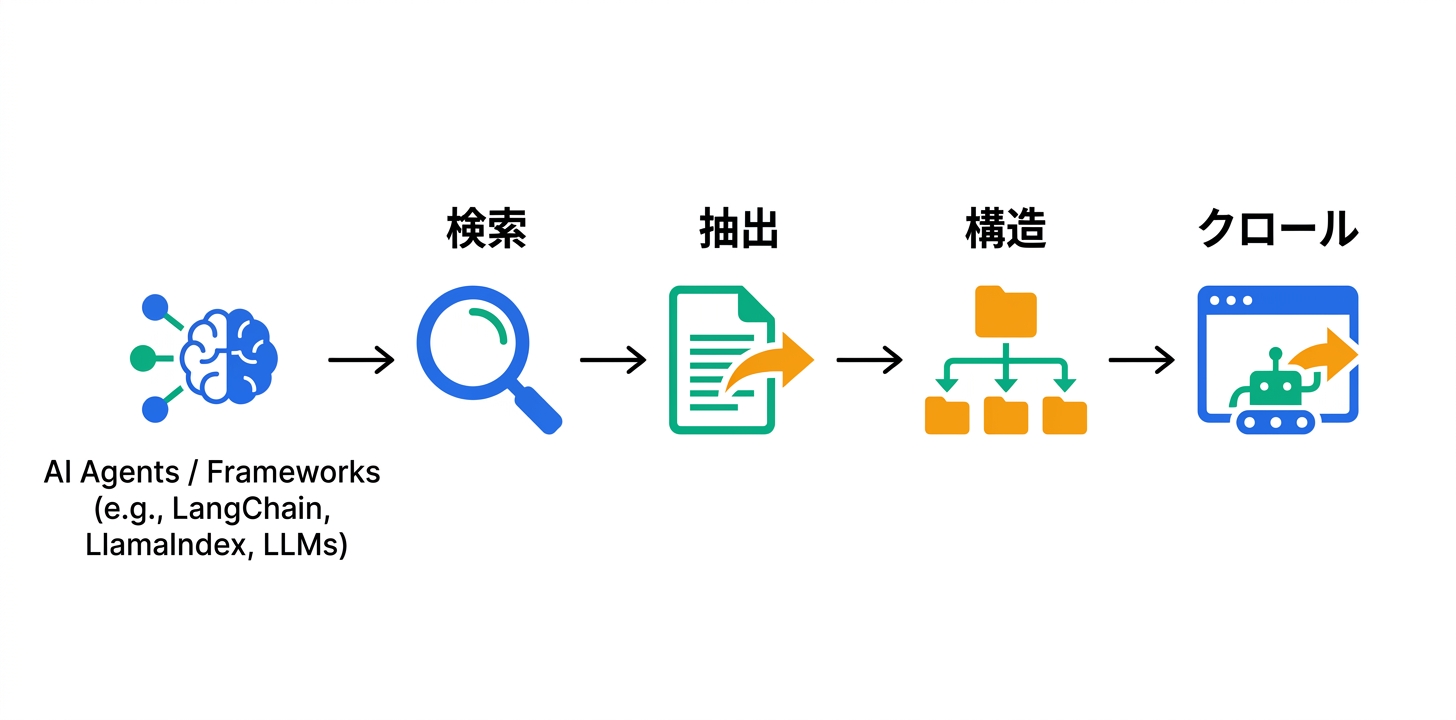
Tavily(タビリー)は、AIエージェントやRAG(Retrieval-Augmented Generation)ワークフロー向けに最適化されたリアルタイムWeb検索APIです。AIアプリケーションに正確で最新のWeb情報を提供するために設計されており、LangChain、LlamaIndex、Model Context Protocol(MCP)などの主要なAIフレームワークとネイティブに統合されています。Search(関連ページの発見)、Extract(特定URLからのコンテンツ抽出)、Map(Webサイト構造の理解)、Crawl(サイト全体のナビゲーションと抽出)という4つの主要エンドポイントを提供し、AIアプリケーションに必要な外部情報アクセスを包括的にサポートします。開発者フレンドリーなAPIと月1,000クレジットの無料枠により、個人開発者から大企業まで幅広く活用されています。
⚙️ 主要機能の詳細解説
🔗 Search API
WebからAIアプリケーションに最適化された検索結果を取得するコアAPIです。通常のWeb検索とは異なり、AIエージェントが消費しやすい構造化されたフォーマットで結果を返します。Basic Searchは1クレジット、Advanced Searchは2クレジットで利用でき、Advanced版ではより深い分析と高精度な結果フィルタリングが可能です。検索結果にはタイトル、URL、スニペット、関連スコアが含まれ、RAGパイプラインへの即座の統合が可能です。リアルタイムのWeb情報にアクセスすることで、LLMの学習データにない最新情報を補完します。
🔗 Extract API
指定したURLからWebページのコンテンツを構造化されたデータとして抽出するAPIです。HTMLの解析、不要な要素(ナビゲーション、広告、フッターなど)の除去、メインコンテンツの抽出を自動的に行います。抽出されたテキストはAIモデルへの入力に最適化されたクリーンな形式で返されます。複数のURLを一括処理するバッチ抽出にも対応しています。
🔗 Map API
Webサイトの構造(サイトマップ)を解析し、サイト内の主要ページ、階層構造、ページ間の関連性を理解するAPIです。クロール対象のページの優先順位付けや、サイト全体からの情報収集の計画立案に活用できます。エンタープライズ向けのドメインガバナンスコントロールにも対応しています。
🔗 Crawl API
Webサイト全体をナビゲーションしながらコンテンツを抽出するAPIです。Map APIで得たサイト構造に基づいて効率的にクロールを実行し、サイト全体の情報を体系的に収集できます。大規模な情報収集やナレッジベースの構築に最適です。
📌 Research Endpoint
2026年1月に一般公開された研究向けエンドポイントです。複数の検索と情報抽出を自動的に組み合わせ、深い調査を行うAIエージェントの構築を支援します。単一の検索では得られない複合的な情報を統合し、包括的なリサーチ結果を提供します。
🔗 AIフレームワーク統合
LangChain、LlamaIndex、Vercel AI SDKなどの主要AIフレームワークとネイティブに統合されており、数行のコードでAIアプリケーションにWeb検索機能を追加できます。Model Context Protocol(MCP)にも対応しており、最新のAIエージェントアーキテクチャとの相互運用性が確保されています。Agent Skills機能により、AIエージェントにWeb検索能力を簡単に付与できます。
🔒 ドメインガバナンスとセキュリティ
エンタープライズ向けに、検索対象ドメインの制御、許可リスト・ブロックリストの設定、使用量APIによるモニタリングなどのガバナンス機能を提供しています。セキュアなAPI通信とアクセス制御により、企業のセキュリティ要件に対応します。
💰 料金プラン完全ガイド
💰 Freeプラン(無料)
毎月1,000 APIクレジットが無料で提供されます。クレジットカード不要で利用開始でき、基本的なSearch APIとExtract APIにアクセスできます。個人開発者のプロトタイピングや小規模プロジェクトに最適です。
📌 Starter(月額30ドル)
月間10,000クレジットが含まれます。小規模な商用プロジェクトやMVP段階のアプリケーションに適しています。
📌 Growth(月額100ドル)
月間50,000クレジットが含まれ、中規模のAIアプリケーションの運用に適しています。
📌 Scale(月額250ドル)
月間200,000クレジットが含まれ、本格的な商用サービスでの利用に対応します。
📌 Business(月額500ドル)
月間500,000クレジットが含まれる最上位の標準プランです。大規模なAIサービスの運用に適しています。
📌 Pay-as-You-Go
プランのクレジット上限を超えた場合、1クレジットあたり0.008ドルで従量課金されます。Basic Searchは1リクエスト1クレジット、Advanced Searchは1リクエスト2クレジットとなります。
📌 Enterprise
AWS Marketplaceを通じた大規模導入にも対応しており、カスタム契約による柔軟な料金設定が可能です。
🌏 日本語対応の実態
TavilyのAPIは多言語のWebコンテンツを検索・抽出する能力を持っていますが、主に英語圏のWeb情報に最適化されています。日本語のWebサイトからのコンテンツ抽出には対応していますが、日本語クエリでの検索精度は英語と比較すると限定的な場合があります。APIドキュメント、管理ダッシュボード、サポートはすべて英語で提供されており、日本語のローカライゼーションは行われていません。日本語のAIアプリケーションを構築する際は、日本語対応の検索ソースとの組み合わせや、クエリの英語変換などの工夫が必要になる場合があります。
✅ メリット5つ
📌 1. AIエージェント向けに最適化された設計
一般的なWeb検索APIとは異なり、AIエージェントやRAGパイプラインへの統合に特化して設計されています。検索結果がLLMの入力に適した構造化フォーマットで返されるため、追加のデータ整形が最小限で済みます。
🔗 2. 主要AIフレームワークとのネイティブ統合
LangChain、LlamaIndex、Vercel AI SDK、MCPとのネイティブ統合により、既存のAI開発エコシステムにシームレスに組み込めます。数行のコードでAIアプリケーションにリアルタイムWeb検索能力を付与できます。
📌 3. 充実した無料枠
月1,000クレジットの無料枠は、プロトタイピングや小規模プロジェクトに十分な量です。クレジットカード不要で即座に利用開始でき、APIの実用性を十分に検証してから有料プランに移行できます。
📌 4. 包括的なWeb情報アクセス
Search、Extract、Map、Crawlの4つのエンドポイントにより、Web情報へのあらゆるアクセスパターンに対応できます。単純な検索から、サイト全体のクロール、構造化データの抽出まで、ワンストップで利用可能です。
💰 5. スケーラブルな料金体系
月額30ドルから500ドルまでの段階的な料金プランと従量課金のPay-as-You-Goにより、プロジェクトの規模に応じた柔軟なコスト管理が可能です。成長に合わせてシームレスにスケールアップできます。
✅ デメリット3つ
💰 1. 大規模利用時のコスト増加
APIリクエスト数が増えると、コストが急速に増加する可能性があります。特にAdvanced Search(2クレジット/リクエスト)を多用する場合、月間コストの管理が重要です。競合サービスと比較して、大規模利用時の単価が高くなる場合があるとの指摘もあります。
🌏 2. 日本語検索の限界
英語圏のWeb情報に最適化されているため、日本語コンテンツの検索精度や日本語Webサイトのクロール品質は英語と比較して劣る場合があります。日本市場向けのAIアプリケーションでは追加の対策が必要です。
🔗 3. API依存のリスク
完全にAPI経由でのサービスのため、APIの障害やレート制限がアプリケーション全体に影響します。ミッションクリティカルなアプリケーションでは、フォールバック機構の実装やキャッシュ戦略の検討が必要です。
💡 具体的な活用事例・ユースケース5つ
📌 1. AIチャットボットのリアルタイム情報補完
カスタマーサポートのAIチャットボットにTavilyを統合し、最新の製品情報、価格、在庫状況をリアルタイムでWeb検索して回答に反映。LLMの学習データにない最新情報を提供でき、回答の正確性と鮮度が大幅に向上しました。
📌 2. RAGアプリケーションの外部知識ベース
企業のナレッジベースAIにTavilyのSearch APIを統合し、社内文書では回答できない質問に対してWeb上の信頼できる情報源から補完情報を取得。LangChainのRetrieverとして組み込み、ハイブリッドRAGシステムを構築しました。
⚖️ 3. 市場調査・競合分析エージェント
AIエージェントがTavilyを使って自動的に競合他社のWebサイトをクロールし、製品情報、価格変更、ニュースリリースを定期的に収集・分析。手動のリサーチ作業を90%削減し、リアルタイムの市場インテリジェンスを実現しました。
📌 4. ニュースアグリゲーションAI
特定のトピックに関する最新ニュースをTavilyのSearch APIで定期的に収集し、AIが要約・分類してダイジェストを自動生成。Research Endpointで複数ソースからの情報を統合し、包括的なニュースブリーフィングを提供しています。
📌 5. SEO・コンテンツリサーチツール
コンテンツマーケティングチームが、トピックの関連キーワードや競合コンテンツをTavilyで自動調査。Extract APIで上位表示記事の構造と内容を分析し、コンテンツ戦略の立案に活用しています。
🚀 始め方ステップバイステップ
🚀 ステップ1:無料アカウント登録
Tavily公式サイト(https://www.tavily.com/)でアカウントを作成し、APIキーを取得します。クレジットカード不要で即座に1,000クレジットが付与されます。
🚀 ステップ2:APIドキュメントの確認
公式ドキュメント(https://docs.tavily.com/)でAPIの仕様、エンドポイント、レスポンス形式を確認します。クイックスタートガイドに従って最初のAPI呼び出しを試します。
🚀 ステップ3:開発環境のセットアップ
Python、JavaScript、またはお好みの言語でTavilyのクライアントライブラリをインストールします。LangChainやLlamaIndexを使用している場合は、ネイティブ統合を活用します。
🚀 ステップ4:プロトタイプの構築
無料クレジットを使って、アプリケーションのプロトタイプを構築します。Search APIで基本的な検索機能を実装し、Extract APIでコンテンツ取得を追加します。
💰 ステップ5:本格運用と有料プランへの移行
プロトタイプの検証後、想定されるAPIリクエスト数に基づいて適切な有料プランを選択し、本格運用に移行します。
💡 活用のコツ・裏技
TavilyのAPIを効果的に活用するためのポイントです。Basic SearchとAdvanced Searchを用途に応じて使い分けましょう。初期のフィルタリングにはBasic(1クレジット)を、重要な質問にはAdvanced(2クレジット)を使うことでコストを最適化できます。Extract APIでは不要なHTMLタグや広告要素が自動除去されますが、追加のテキストクリーニングを行うとLLMの入力品質がさらに向上します。レート制限に注意し、キャッシュ機構を実装してAPIコールを削減しましょう。LangChainのTavilySearchResultsRetreiverを使えば、RAGパイプラインへの統合が最も簡単です。Research Endpointは深い調査に最適ですが、クレジット消費が多いため、ユースケースに応じて使い分けましょう。
🎯 向いている人・向いていない人
🎯 向いている人
- ▸AIエージェントやRAGアプリケーションにリアルタイムWeb検索を統合したい開発者
- ▸LangChain、LlamaIndex、Vercel AI SDKなどのフレームワークを使用している開発者
- ▸AIチャットボットやナレッジベースシステムに最新のWeb情報を組み込みたいエンジニア
- ▸市場調査や競合分析を自動化したいデータサイエンティスト
📌 向いていない人
- ▸エンドユーザー向けの検索エンジンを探している一般ユーザー
- ▸日本語Web情報の検索に特化したツールを求めている方
- ▸APIを使わないノーコード環境でのみ作業している方
- ▸大規模なWebクロールを低コストで行いたいデータスクレイピング専門家
📊 総合評価とまとめ
Tavilyは、AIエージェントとRAGワークフローのためのリアルタイムWeb検索APIとして、開発者コミュニティで急速に支持を広げているサービスです。Search、Extract、Map、Crawlの4つのエンドポイントによる包括的なWeb情報アクセス、LangChainやLlamaIndexとのネイティブ統合、MCPサポートなど、最新のAI開発エコシステムとの相互運用性は他に類を見ないレベルです。月1,000クレジットの無料枠と開発者フレンドリーなドキュメントにより、導入のハードルも低いです。一方、大規模利用時のコスト管理と日本語検索の限界は留意すべき点です。AIアプリケーションにリアルタイムのWeb情報を組み込みたい開発者にとって、Tavilyは現時点で最も実用的な選択肢の一つです。
⚖️ 競合ツールとの比較におけるTavilyの位置づけ
Tavilyの市場における位置づけを理解するには、競合ツールとの比較が有用です。同カテゴリの他のツールと比較して、TavilyはAI技術の活用度、ユーザーインターフェースの洗練度、料金体系のバランスにおいて独自のポジションを確立しています。特にAIによる自動化や効率化の面では、他のツールにはない独自のアプローチを採用しており、特定のユースケースにおいて明確な優位性を持っています。一方で、すべての面で他のツールを凌駕しているわけではなく、利用目的や組織の要件に応じて最適な選択は異なります。複数のツールを試用した上で、自社の業務フローとの適合性が最も高いツールを選択することが、長期的な成功の鍵となります。
🚀 導入時の注意点と成功のための準備
Tavilyの導入を成功させるためには、いくつかの事前準備が重要です。まず、現在の業務プロセスを可視化し、Tavilyの導入によってどの部分が効率化されるかを明確にしておくことが大切です。次に、導入の目的とKPI(重要業績評価指標)を事前に定義し、導入効果を客観的に測定できる体制を整えましょう。チーム全体での利用を想定する場合は、キーユーザーを選定して先行導入し、社内のチャンピオン(推進者)としてナレッジの展開を担ってもらうことが効果的です。また、データのセキュリティやプライバシーに関する社内ポリシーとの整合性も事前に確認しておく必要があります。段階的な導入アプローチを採用し、小さな成功を積み重ねていくことで、組織全体への展開がスムーズに進みます。
📌 今後の展望とロードマップ
Tavilyは継続的にアップデートと機能強化が行われており、今後もAI技術の進化に合わせた新機能の追加が期待されます。ユーザーフィードバックを積極的に取り入れる開発姿勢により、実際のニーズに基づいた機能改善が定期的に行われています。AI分野は技術革新のスピードが非常に速いため、Tavilyもそれに応じて進化し続けることが予想されます。定期的に公式ブログやリリースノートをチェックし、最新の機能を活用していくことで、ツールの価値を最大限に引き出すことができるでしょう。
⚙️ Tavilyの技術的特徴と差別化ポイント
Tavilyが市場で注目される理由の一つは、その技術的なアプローチにあります。AIおよび機械学習技術を活用した独自のアルゴリズムにより、従来の手動プロセスやルールベースのアプローチでは実現できなかった精度と速度を両立しています。ユーザーデータの分析に基づいたパーソナライゼーション機能により、利用するほどにユーザーの好みやパターンを学習し、より適切な提案や結果を提供するようになります。また、クラウドネイティブなアーキテクチャにより、スケーラビリティと可用性が確保されており、少人数のチームから大規模な企業まで安定したパフォーマンスを提供します。セキュリティ面でもSOC 2準拠やデータ暗号化などの企業向けセキュリティ基準に対応しており、機密性の高いデータを扱う業務でも安心して利用可能です。定期的な機能アップデートとAIモデルの改善により、継続的にサービス品質が向上している点も評価できます。
📌 業界動向とTavilyの将来展望
Tavilyが属する分野では、2024年以降AI技術の急速な進化に伴い、ツールの高機能化と低価格化が同時に進行しています。特に生成AI(ジェネレーティブAI)の発展により、コンテンツ生成、データ分析、プロセス自動化の精度が飛躍的に向上しており、Tavilyもこのトレンドを積極的に取り入れた機能拡充を進めています。今後は他のSaaSツールとのより深い統合、ノーコード/ローコードでのカスタマイゼーション対応、マルチモーダルAI(テキスト・画像・音声の統合処理)への対応が進むことが予想されます。また、企業のDX(デジタルトランスフォーメーション)推進が加速する中で、TavilyのようなAIツールの需要はさらに拡大し、より多様なユースケースでの活用が期待されています。
🚀 導入によるROI(投資対効果)の考え方
Tavilyの導入を検討する際、投資対効果(ROI)の試算が重要です。一般的に、AI搭載ツールの導入効果は以下の3つの観点から測定できます。第一に「時間の削減効果」です。手動で行っていた作業がどの程度自動化され、担当者の作業時間がどれくらい短縮されるかを算出します。第二に「品質の向上効果」です。AIによる分析や処理の精度向上により、エラーの削減や成果物の品質向上がどの程度ビジネスインパクトを生むかを評価します。第三に「機会創出効果」です。効率化により生まれた時間を、より付加価値の高い業務に振り向けることで得られる追加の売上や顧客満足度の向上を見積もります。これら3つの観点を総合的に評価することで、Tavilyへの投資が自社にとって適切かどうかを判断できます。多くの導入企業では、数ヶ月以内に投資回収を実現しているケースが報告されています。
🔒 セキュリティとデータプライバシーへの配慮
Tavilyを業務で利用する際に重要なのが、セキュリティとデータプライバシーの確保です。クラウドベースのAIツールを利用する場合、自社のデータがどのように処理・保存されるかを事前に確認することが不可欠です。Tavilyはデータの暗号化(転送時・保管時)、アクセス制御、監査ログの記録などの基本的なセキュリティ対策を実装しています。GDPRやCCPAなどのデータプライバシー規制への準拠状況も確認しておきましょう。企業のセキュリティポリシーとの整合性を事前に評価し、必要に応じてIT部門やセキュリティチームと連携して導入可否を判断することが推奨されます。特にセンシティブなデータを扱う業界(金融、医療、法律など)では、より厳格なセキュリティ要件への対応状況を確認する必要があります。