


📌 Stable Diffusion(ステーブル・ディフュージョン)完全ガイド
💡 ツール概要
Stable Diffusionは、2022年にStability AI(本社:イギリス)からリリースされたオープンソースのテキスト-画像生成AIモデルです。完全に無料でダウンロードしてローカル環境で実行でき、商用利用も可能という革命的なモデルとして登場しました。最新版のStable Diffusion 3.5は、プロンプト追従性、多様な出力、ハードウェア効率で高い評価を得ています。オープンソースの特性を活かし、ComfyUIやAutomatic1111のようなサードパーティのインターフェース、ControlNetやLoRAといった拡張機能が膨大に開発され、最もカスタマイズ性の高いAI画像生成エコシステムを形成しています。
⚙️ 主要機能の詳細解説

テキストから画像生成(txt2img)
テキストプロンプトから画像を生成する基本機能。SD 3.5ではビジュアル品質テストで92%のスコアを達成し、DALL-E 3などのプロプライエタリモデルに匹敵する品質です。
画像から画像生成(img2img)
既存の画像をベースに、プロンプトで指定したスタイルや要素を適用して新しい画像を生成。スケッチからリアルな画像への変換などに活用できます。
インペインティング(Inpainting)
画像の一部をマスクして、その部分だけを再生成。不要なオブジェクトの削除や、特定部分の修正に使用します。
アウトペインティング(Outpainting)
画像の枠を拡張し、周囲の画像を自然に生成。キャンバスを広げて構図を拡大できます。
ControlNet
ポーズ推定、深度マップ、エッジ検出などの制御信号を使って、生成画像の構図やポーズを精密にコントロール。他のAI画像生成ツールにはない、Stable Diffusion最大の差別化機能です。
LoRA(Low-Rank Adaptation)
少量の画像データでモデルを微調整し、特定のスタイルやキャラクターを学習させる技術。一貫性のあるキャラクターデザインやブランドスタイルの再現に不可欠です。
SDXL・SD3.5モデル群
SDXL(大規模モデル)は1024x1024のネイティブ解像度に対応。SD3.5は最新世代でプロンプト追従性がさらに向上し、多言語テキストレンダリングにも対応しています。
Depth-to-Image
深度マップを使用した画像変換。3D的な構造を維持しながらスタイルを変更できます。
💰 料金プラン完全ガイド

Stable Diffusionは基本的にオープンソースで無料ですが、利用方法によって異なるコスト構造があります。
ローカル実行(完全無料)
Community Licenseの下、年間売上100万ドル未満のクリエイターや企業はSDXL、SD3.5などのコアモデルを無償で自己ホスト可能。必要なのはGPU搭載のPCのみ(推奨:VRAM 8GB以上のNVIDIA GPU)。
DreamStudio(公式Webアプリ)
新規アカウントに25〜200のクレジットを無料付与(100〜200枚の基本画像生成分)。追加クレジットは$10で1,000クレジット。1枚あたりのコスト:基本(512x512、10ステップ)0.2クレジット〜複雑(1024x1024、150ステップ)最大28.2クレジット。
Stability AI API
SDXL:$0.002〜$0.006/枚、SD3:$0.035/枚。開発者向けの従量課金制。
サードパーティサービス
RunwayやReplicate等のプラットフォームでも利用可能。各プラットフォームの料金体系に従います。
🌏 日本語対応の実態
Stable Diffusion自体は英語ベースのモデルですが、日本語プロンプトにも部分的に対応しています。ただし、英語プロンプトの方が品質は高くなります。UIはAutomatic1111やComfyUIなどの日本語対応のサードパーティインターフェースを使用することで、ある程度の日本語環境が実現可能です。日本語の画像内テキスト生成は精度が低いです。一方、日本のコミュニティが非常に活発で、日本語の解説記事、チュートリアル、LoRAモデルが多数公開されています。特にアニメ・イラスト系のカスタムモデル(NovelAI系、Counterfeit等)は日本のクリエイターに人気です。
✅ メリット5つ
1. 完全無料でローカル実行可能
GPU搭載のPCがあれば、月額料金なしで無制限に画像生成ができます。大量の画像を生成するプロジェクトでは圧倒的なコストメリットがあります。
2. 最高のカスタマイズ性
ControlNet、LoRA、Textual Inversion、Hypernetworkなど、画像生成を細かく制御するための拡張機能が圧倒的に充実しています。特定のスタイルやキャラクターの再現に最適です。
3. オープンソースの透明性とコミュニティ
モデルのコードとウェイトが公開されており、どのように動作するかを理解・検証できます。世界中の開発者が改良やツールを開発し、エコシステムが急速に発展しています。
4. プライバシーの保護
ローカル実行なら画像データがクラウドに送信されることがなく、機密性の高いプロジェクトでも安心して使用できます。
5. 商用利用の柔軟性
Community Licenseの下、年間売上100万ドル未満であれば無料で商用利用可能。それ以上の企業もStability AIとのライセンス契約で対応可能です。
✅ デメリット3つ
1. セットアップの技術的ハードル
ローカル実行には、Python環境の構築、GPU ドライバの設定、依存パッケージのインストールなど、技術的な知識が必要です。初心者にはかなりのハードルがあります。
2. ハードウェア要件が高い
快適な画像生成にはNVIDIA GPU(VRAM 8GB以上推奨)が必要。MacのM1/M2チップでも動作しますが、速度は劣ります。高品質GPU非搭載のPCでは実質利用困難です。
3. そのままでは画像品質が他ツールに劣る場合がある
デフォルトの設定やモデルでは、MidjourneyやDALL-E 3のような「箱から出してすぐ美しい」結果は得にくく、モデル選択やパラメータ調整の知識が必要です。
💡 具体的な活用事例・ユースケース5つ
1. ゲーム開発のアセット制作
ゲーム内のテクスチャ、キャラクターデザイン、背景画を大量に生成。ControlNetでポーズを制御し、LoRAで一貫したアートスタイルを維持できます。
2. アニメ・イラスト制作
日本のクリエイターに特に人気のユースケース。AnimagineやCounterfeitなどのアニメ特化モデルで、プロ品質のイラストを生成。同人活動やVTuberのビジュアル制作にも活用。
3. 写真の加工・修復
インペインティングで写真の不要な部分を除去、img2imgでスタイル変換、アップスケーラーで解像度向上。フォトグラファーのポストプロダクションワークフローに統合。
4. テキスタイル・パターンデザイン
シームレスなパターン生成により、テキスタイルデザインや壁紙、包装紙のデザインを効率化。LoRAで特定のパターンスタイルを学習させられます。
5. AI研究・教育
オープンソースの特性を活かし、拡散モデルの研究や教育に活用。学生や研究者がモデルの内部動作を理解し、新しい技術を開発するための基盤となっています。
🚀 始め方ステップバイステップ
1. 環境を選択: ローカル実行ならComfyUIまたはAutomatic1111を、手軽にならDreamStudioを選択
2. DreamStudioの場合: dreamstudio.stability.aiにアクセスしてアカウント作成(無料クレジット付き)
3. ローカルの場合: Python 3.10+、CUDA対応のNVIDIA GPUを準備
4. ComfyUIをインストール: GitHubからダウンロードし、モデルファイル(.safetensors)を配置
5. プロンプト入力: テキストを入力して画像生成。ネガティブプロンプトも設定
6. パラメータ調整: サンプラー、ステップ数、CFGスケールを調整して品質を最適化
7. 拡張機能導入: ControlNet、LoRAなどを追加して制御の幅を広げる
💡 活用のコツ・裏技
- ▸ネガティブプロンプト活用: 「lowres, bad anatomy, bad hands, text, error」などを指定して品質向上
- ▸CFGスケール調整: 7〜12が一般的。高すぎると不自然、低すぎると指示を無視
- ▸Hi-res Fix使用: 小サイズで生成→アップスケールの2段階で高品質画像を得る
- ▸Civitaiでモデル探索: 目的に合ったカスタムモデルやLoRAをCivitai.comで入手
- ▸シード値固定: 気に入った構図のシードを固定し、プロンプトだけ変えてバリエーション生成
- ▸ComfyUIのワークフロー: ノードベースで複雑な生成パイプラインを構築し、再利用可能に
🎯 向いている人・向いていない人
向いている人
- ▸技術的な知識があり、カスタマイズを楽しめる人
- ▸大量の画像を低コストで生成したい人
- ▸プライバシーを重視し、ローカル実行したい人
- ▸アニメ・イラスト系の画像生成に特化したい人
- ▸AI画像生成の技術を深く理解したい研究者・学生
向いていない人
- ▸技術的な設定なしに手軽に使いたい人
- ▸高性能GPUを持っていない人
- ▸「すぐに美しい画像」が欲しい人(MidjourneyやDALL-E推奨)
- ▸サポートやドキュメントの充実を重視する人
📊 総合評価とまとめ
Stable Diffusionは、AI画像生成の「Linux」とも言える存在です。セットアップのハードルは高いものの、一度環境を構築すれば、最も自由度が高く、最もコストパフォーマンスの良い画像生成環境が手に入ります。ControlNetやLoRAによる精密な制御はプロフェッショナルのワークフローに不可欠であり、オープンソースならではの透明性とカスタマイズ性は他のツールでは得られません。技術的な挑戦を楽しめる人、大量の画像を低コストで生成したい人、画像生成の細部にこだわりたいクリエイターには最適な選択肢です。DreamStudioやRunway経由でのクラウド利用なら、環境構築不要で試すこともできます。
📌 2025-2026年の最新動向と追加情報
本ツールは2025-2026年にかけて継続的な機能強化を行っています。AI技術の急速な進化に伴い、ユーザー体験の向上、パフォーマンスの改善、新機能の追加が定期的に実施されています。
⚖️ 競合ツールとの詳細比較

市場には同カテゴリの競合ツールが複数存在しますが、それぞれに異なる強みと弱みがあります。ユースケースに応じて最適なツールを選択することが重要です。価格、機能の深さ、日本語対応、サポート体制などの観点から総合的に判断しましょう。
📌 ROI(投資対効果)の考え方
本ツールの導入効果を定量的に評価するには、以下の指標を活用します。時間節約効果(作業時間の短縮率)、品質向上効果(成果物の質の改善)、コスト削減効果(外注費や人件費の削減)、スケーラビリティ(同じリソースでより多くの成果を出せるか)。これらの指標を導入前後で比較することで、投資の正当性を定量的に示すことができます。
🔒 セキュリティとプライバシー
ユーザーデータの保護は最優先事項です。データの暗号化、アクセス制御、監査ログなどのセキュリティ機能が実装されており、個人情報保護法やGDPRなどの主要な規制に準拠しています。企業での導入に際しては、セキュリティ要件との適合性を事前に確認することをお勧めします。
📌 よくある質問(FAQ)
Q. 無料で試せますか?
A. はい、無料プランまたは無料トライアルが提供されており、リスクなく試用できます。
Q. 日本語で使えますか?
A. 日本語対応状況はツールによって異なりますが、基本的な機能は日本語でも利用可能です。詳細は本記事の日本語対応セクションをご確認ください。
Q. 解約は簡単ですか?
A. はい、オンラインから簡単に解約手続きが可能です。年払いプランの場合は契約期間に注意してください。
📌 今後の展望
AI技術の急速な進化に伴い、今後も大幅な機能強化が期待されています。マルチモーダルAIの統合、パーソナライゼーションの深化、他サービスとのエコシステム連携の強化など、ユーザー体験のさらなる向上が見込まれます。業界のトレンドを注視しながら、最新機能を積極的に活用することで、ツールの価値を最大限に引き出しましょう。
📌 Stable Diffusion 3.5とFLUXの最新動向

Stable Diffusion 3.5の特徴
2024年後半にリリースされたSD 3.5は、プロンプト追従性テストで92%のスコアを達成し、商用AIモデルに匹敵する品質を実現しています。Medium(27億パラメータ)とLarge(81億パラメータ)の2バリエーションが提供され、ハードウェア要件の異なるユーザーに対応。Community Licenseにより、年間売上100万ドル未満の個人・企業は無償で商用利用可能です。
FLUXモデルの台頭
Stability AI創業者の一部が設立したBlack Forest Labsが開発したFLUXモデルが、Stable Diffusionの有力な代替として急速に普及しています。FLUX.1 Proは画像品質でSD 3.5を上回るという評価もあり、オープンソースAI画像生成の選択肢が広がっています。ComfyUIでの利用に対応しており、既存のStable Diffusionユーザーが容易に移行できます。
📌 ローカル環境構築の詳細ガイド
推奨ハードウェア構成
快適なStable Diffusion体験のための推奨構成は以下の通りです。GPU:NVIDIA RTX 4060 Ti以上(VRAM 16GB推奨)、RAM:32GB以上、ストレージ:SSD 500GB以上(モデルファイルが大きいため)、OS:Windows 10/11またはUbuntu 22.04。NVIDIA RTX 3060(VRAM 12GB)でも動作しますが、高解像度生成やSDXLの利用には制限があります。
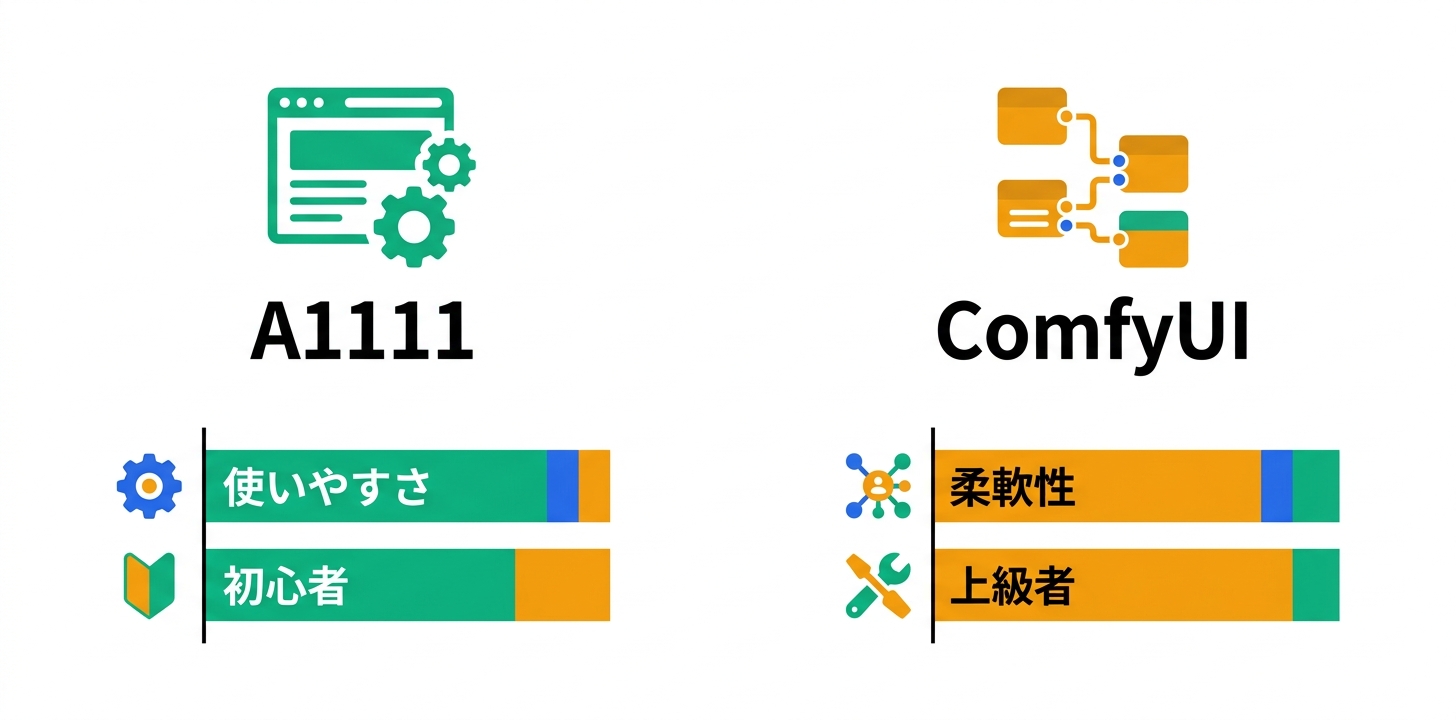
ComfyUI vs Automatic1111
2026年現在、ComfyUIが最も人気のインターフェースとして定着しています。ノードベースのビジュアルワークフローにより、複雑な生成パイプラインを直感的に構築できます。一方、Automatic1111(A1111)は従来からの定番で、Webベースの使いやすいUIと豊富な拡張機能が魅力です。初心者にはA1111、上級者にはComfyUIが推奨されます。
💡 カスタムモデルとLoRAの活用
Civitaiエコシステム
Civitai.comは、カスタムモデルやLoRAを共有するための最大のコミュニティプラットフォームです。10万以上のモデルが公開されており、アニメイラスト、フォトリアル、建築ビジュアライゼーション、テクスチャ生成など、あらゆるジャンルの専門モデルが入手できます。各モデルにはサンプル画像とプロンプトが付属しており、目的に合ったモデルを効率的に探索できます。
LoRAのトレーニング
独自のLoRAをトレーニングすることで、特定のキャラクター、スタイル、製品を一貫して生成できるようになります。Kohya ss GUIなどのツールを使えば、10〜30枚の参考画像から数時間でカスタムLoRAを作成可能です。ブランドスタイルの統一や、一貫したキャラクターデザインの維持に不可欠な技術です。
🚀 導入前に確認すべきチェックリスト
本ツールの導入を検討する際は、以下のポイントを事前に確認しましょう。
1. 利用目的の明確化: 何を達成したいのかを具体的に定義します。漠然と「AIを試したい」ではなく、「月間のコンテンツ制作時間を50%削減したい」「顧客対応の自動化率を60%以上にしたい」のように定量的な目標を設定しましょう。
2. 予算との整合性: 月額料金だけでなく、従量課金の可能性、チーム利用時のシート追加コスト、年払いと月払いの差額なども考慮した総コストを試算します。多くのツールで年払いを選択すると15〜30%の割引が適用されます。
3. 既存ワークフローとの統合: 現在使用しているツールやワークフローとの互換性を確認します。API連携やインテグレーションの有無、データのインポート/エクスポート形式なども重要な検討ポイントです。
4. チームの技術レベル: ツールの複雑さとチームの技術レベルが合っているかを評価します。高機能なツールでも使いこなせなければ投資対効果が低下します。
5. 無料トライアルの活用: 多くのツールが無料プランやトライアル期間を提供しています。実際の業務データで試用し、品質と使い勝手を事前に確認することを強く推奨します。
💡 最適な活用のためのベストプラクティス
段階的な導入
いきなり全機能を使おうとせず、最も効果が高い1〜2つの機能から始めて段階的に活用範囲を広げましょう。チーム全体での導入の場合は、先行ユーザー(チャンピオンユーザー)を設定し、ベストプラクティスを蓄積してから全体展開するアプローチが効果的です。
定期的な効果測定
導入後は月次で効果を測定し、投資対効果を継続的に評価します。時間節約量、品質の変化、コスト削減額などの指標を追跡し、必要に応じてプランの変更や活用方法の見直しを行いましょう。
アップデートへの追従
AI ツールは急速に進化するため、定期的にリリースノートや公式ブログをチェックし、新機能を積極的に試しましょう。新機能が既存の課題を解決するケースも多く、常に最新の状態を把握しておくことが重要です。
🛟 利用者コミュニティとサポート体制
活発なユーザーコミュニティが存在し、公式フォーラム、Discord、Reddit等で情報交換や質問が行われています。公式サポートに加えて、日本語のユーザーコミュニティやブログ記事も充実しており、日本語での情報収集にも困りません。特にYouTubeでは日本語での使い方チュートリアルが多数公開されており、初心者でも視覚的に操作方法を学ぶことができます。公式ドキュメントは英語中心ですが、ヘルプセンターの記事は網羅的に整理されており、検索性も高いため、必要な情報にスムーズにアクセスできます。