


💡 ツール概要
ELYZA LLM(イライザ エルエルエム)は、東京大学松尾研究室発のAIスタートアップ株式会社ELYZAが開発する日本語特化型の大規模言語モデル(LLM)です。日本語における対話・テキスト生成・要約・分類・情報抽出などのタスクにおいて、グローバルの海外製LLMに匹敵する高い性能を実現しています。2025年7月に基盤モデルを「Llama-3.1-ELYZA-JP-70B」から「ELYZA-Shortcut-1.0-Qwen-32B」に刷新し、性能と効率の両立を達成しました。さらに2026年1月には、日本語における知識・指示追従能力を強化した拡散大規模言語モデル(dLLM)「ELYZA-LLM-Diffusion」シリーズを商用利用可能な形で公開し、業界に大きなインパクトを与えました。金融業界をはじめとする大企業での本番運用実績を持つ高い安全性・信頼性を備えたLLM基盤として、日本企業のAI活用を強力に支援しています。KDDIグループの一員として企業のDX推進パートナーとしてのポジションも確立しています。国産LLMとして日本語処理の品質と安全性にこだわり、海外LLMでは対応しきれない日本語特有のニュアンスや業界専門用語への深い理解を持つ点が最大の差別化ポイントです。
⚙️ 主要機能の詳細解説
🌏 日本語特化の高精度テキスト生成
ELYZA LLMは日本語のテキスト生成において、GPT-4やClaude 3と同等レベルの品質を実現しています。ビジネス文書の作成、メールの起草、報告書の要約、議事録の生成、FAQの作成など、企業の日常業務で発生するあらゆるテキスト生成タスクに対応します。日本語の敬語体系、ビジネス慣習に沿った表現、業界固有の専門用語を適切に使い分ける能力は、海外製LLMを大きく上回ります。
📌 複雑なタスクの実行と高精度な対話
単純な質問応答だけでなく、複数ステップの推論、条件分岐を含む指示の遂行、コンテキストを踏まえた継続的な対話など、複雑なビジネスタスクの実行に対応します。法務文書のレビュー支援、契約書のリスク分析、マーケティング戦略の立案支援など、高度な知識と判断力が求められるタスクにも活用されています。
📌 ELYZA-LLM-Diffusion(拡散言語モデル)
2026年1月に公開されたELYZA-LLM-Diffusionは、従来の自己回帰型(次のトークンを1つずつ生成する方式)とは異なる拡散モデルベースのテキスト生成を採用した革新的なモデルです。テキスト全体を並列に生成する手法により、高速な文章生成と高い品質の両立を実現します。商用利用可能なライセンスで公開されており、企業の自社システムへの組み込みが可能です。
🔗 API提供と企業システム統合
ELYZA LLMはAPI経由での利用が可能で、企業の既存システム(CRM、ERP、社内ポータル、カスタマーサポートシステム等)への統合が柔軟に行えます。金融業界をはじめとする大企業での本番運用実績に裏打ちされた高い安定性とセキュリティを備えており、ミッションクリティカルな業務への適用にも耐えうる信頼性を提供します。
📌 カスタマイズとファインチューニング
企業固有のドメイン知識(業界用語、社内ルール、商品知識等)を学習させるファインチューニングに対応しており、汎用LLMでは対応しきれない専門性の高いタスクへの適応が可能です。金融、法務、医療、製造業などの業界特化型モデルの構築実績があります。
🔒 セキュリティとコンプライアンス
日本国内でのデータ処理を前提とした運用が可能で、個人情報保護法やGDPRへの対応、金融庁ガイドラインへの準拠など、日本企業が求めるコンプライアンス要件を満たすように設計されています。オンプレミス環境やプライベートクラウドでの運用にも対応し、データの外部流出リスクを最小化します。
📌 デモ版での体験
ELYZA公式サイトで無料のデモ版が公開されており、ELYZA LLMの日本語テキスト生成能力を手軽に試すことができます。登録不要でアクセスでき、文章生成、要約、質問応答などの基本機能を体験できます。
📌 文書要約・情報抽出
長文の報告書、論文、ニュース記事、契約書などを高精度に要約する機能を持ちます。単なる文章の短縮ではなく、文脈を理解した上での重要ポイントの抽出と構造化された要約を生成します。大量の文書を効率的に処理する業務において大きな生産性向上をもたらします。
💰 料金プラン完全ガイド
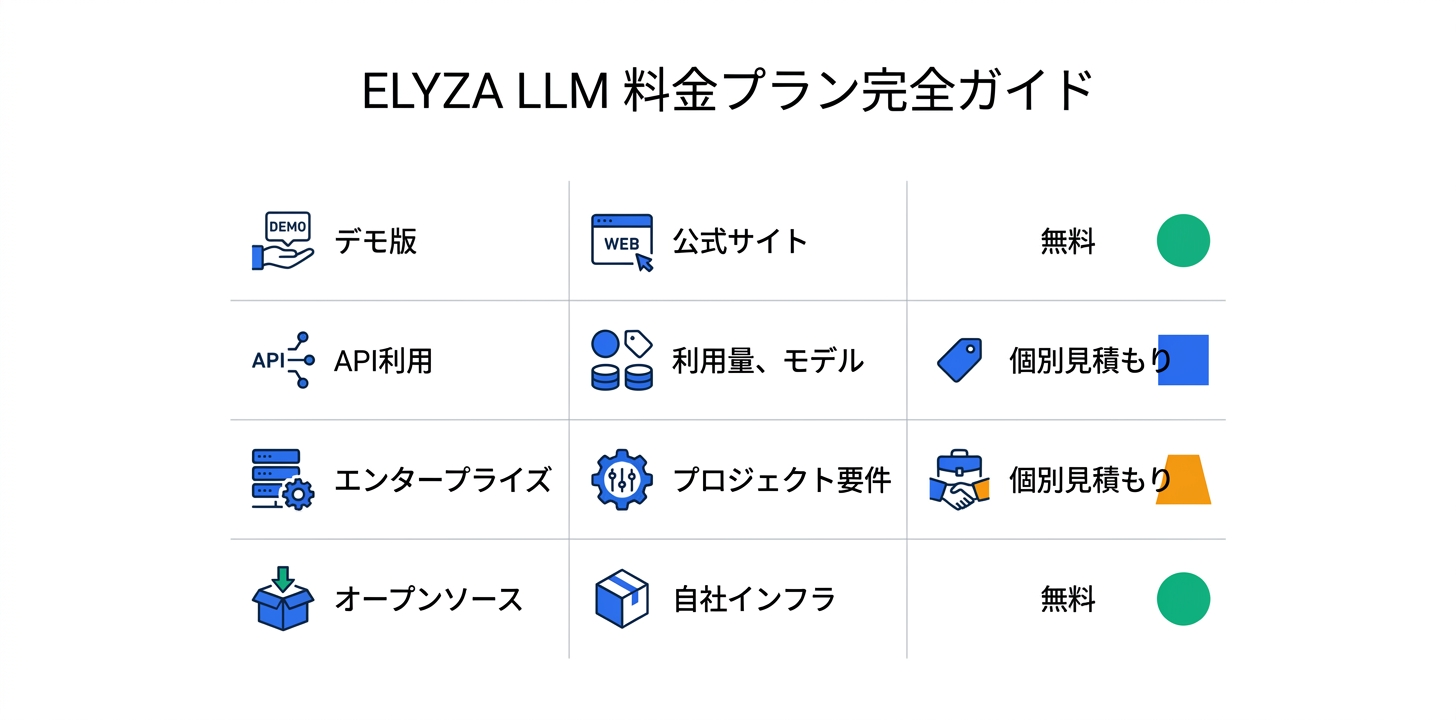
ELYZA LLMの料金は、法人向けのカスタム見積もりが基本となっています。
デモ版(無料)
ELYZA公式サイトのデモページで、ELYZA LLMの基本機能を無料で体験できます。テキスト生成、要約、質問応答などの機能を試用でき、導入前の評価に活用可能です。
API利用(個別見積もり)
APIの利用料金は、利用量(トークン数)、モデルの種類、SLA要件、セキュリティ要件に応じた個別見積もりとなります。ELYZAの営業チームに直接お問い合わせが必要です。
エンタープライズ導入(個別見積もり)
大規模な企業導入、オンプレミス運用、カスタムファインチューニング、専任サポートを含む包括的なエンタープライズパッケージは、プロジェクトの規模と要件に基づいたカスタム見積もりとなります。
オープンソースモデル(無料)
ELYZA-LLM-Diffusionシリーズなど、一部のモデルは商用利用可能なオープンソースライセンスで公開されており、自社のインフラ上で無料で利用できます。ただし、運用・保守は自社で行う必要があります。
KDDIグループ経由の提供
KDDIグループの法人向けソリューションとして、既存のKDDI法人契約に組み込んだ形でのELYZA LLM提供も可能です。
🌏 日本語対応の実態
ELYZA LLMは日本語に完全特化して開発されたモデルであり、日本語対応は最大の強みです。日本語の敬語体系(尊敬語・謙譲語・丁寧語)の適切な使い分け、ビジネス日本語の定型表現、業界固有の専門用語、日本語特有の曖昧表現の理解、慣用句やことわざの適切な使用など、海外製LLMでは実現困難な高度な日本語処理能力を持ちます。UI、ドキュメント、カスタマーサポートもすべて日本語で提供されており、日本企業にとって言語面での障壁は一切ありません。日本語でのプロンプト入力に対する応答精度は、同クラスの海外LLMを明確に上回る水準にあります。
✅ メリット5つ
🌏 1. 国産LLMならではの日本語処理品質
日本語に特化した訓練データとファインチューニングにより、GPT-4やClaudeと同等以上の日本語テキスト生成品質を実現しています。特に敬語の使い分け、ビジネス文書の作成、業界専門用語の理解において海外製LLMを凌駕します。
📌 2. 大企業での本番運用実績と信頼性
金融業界をはじめとする大企業での本番環境での運用実績があり、ミッションクリティカルな業務への適用に耐えうる安定性と信頼性が実証されています。SLAやセキュリティ要件の厳しい業界でも安心して導入できます。
🌏 3. データの国内処理とコンプライアンス対応
日本国内でのデータ処理を前提とした運用が可能で、個人情報保護法、金融庁ガイドライン、各業界の規制要件に準拠した運用体制を構築できます。海外にデータを送信するリスクを回避したい企業にとって大きなメリットです。
📌 4. KDDIグループのバックアップ
KDDIグループの一員としての資金力、インフラ、法人営業ネットワークに支えられており、スタートアップ特有の事業継続リスクが軽減されています。長期的なパートナーシップを前提とした導入がしやすい安心感があります。
📌 5. オープンソースモデルの提供
ELYZA-LLM-Diffusionをはじめとするモデルが商用利用可能なオープンソースで公開されており、技術力のあるチームは自社インフラ上で自由にカスタマイズ・運用できます。
✅ デメリット3つ
📌 1. 個人ユーザー向けの直接的なサービスが限定的
法人向け(B2B)を主な対象としているため、個人ユーザーがELYZA LLMを日常的に利用できる消費者向けサービスは限定的です。デモ版での体験は可能ですが、ChatGPTやClaudeのような個人向けサブスクリプションは提供されていません。
💰 2. 料金の不透明さ
個別見積もり制のため、導入前にコストの見通しを立てにくい面があります。小規模企業やスタートアップにとっては、予算感の把握が困難で導入検討のハードルになる可能性があります。
⚙️ 3. グローバルLLMと比較した機能の幅
GPT-4やClaudeが持つ画像理解、コード生成、多言語対応などの幅広い機能と比較すると、ELYZA LLMは日本語テキスト処理に特化しており、マルチモーダル対応や英語でのタスク処理では劣る面があります。
💡 具体的な活用事例・ユースケース5つ
📌 1. 金融機関の文書処理自動化
銀行や証券会社の各種報告書、契約書、コンプライアンス文書の要約・分類・リスク分析をELYZA LLMで自動化します。専門的な金融用語への深い理解と、日本の金融規制に準拠した安全な処理が可能です。
🛟 2. カスタマーサポートの高度化
顧客からの問い合わせに対して、日本語の微妙なニュアンスを理解した高品質な回答を自動生成します。敬語の適切な使い分け、感情に配慮した表現、商品知識に基づいた正確な回答により、顧客満足度の向上を実現します。
📌 3. 法務文書のレビュー支援
契約書や利用規約のドラフトをELYZA LLMでレビューし、潜在的なリスクポイントや不明確な条項を自動的に指摘します。法務部門の業務効率を大幅に改善し、レビューの品質と速度を同時に向上させます。
🌏 4. マーケティングコンテンツの日本語生成
日本市場向けのマーケティングコピー、プレスリリース、ブログ記事、SNS投稿を高品質な日本語で生成します。日本の文化的文脈やビジネス慣習を反映した自然な表現が得られます。
📌 5. 社内ナレッジベースの構築
社内文書やマニュアルをELYZA LLMで処理し、従業員が自然言語で質問できる社内ナレッジベースを構築します。新入社員のオンボーディング効率化や、部門横断的な知識共有に貢献します。
⚖️ 競合ツールとの比較
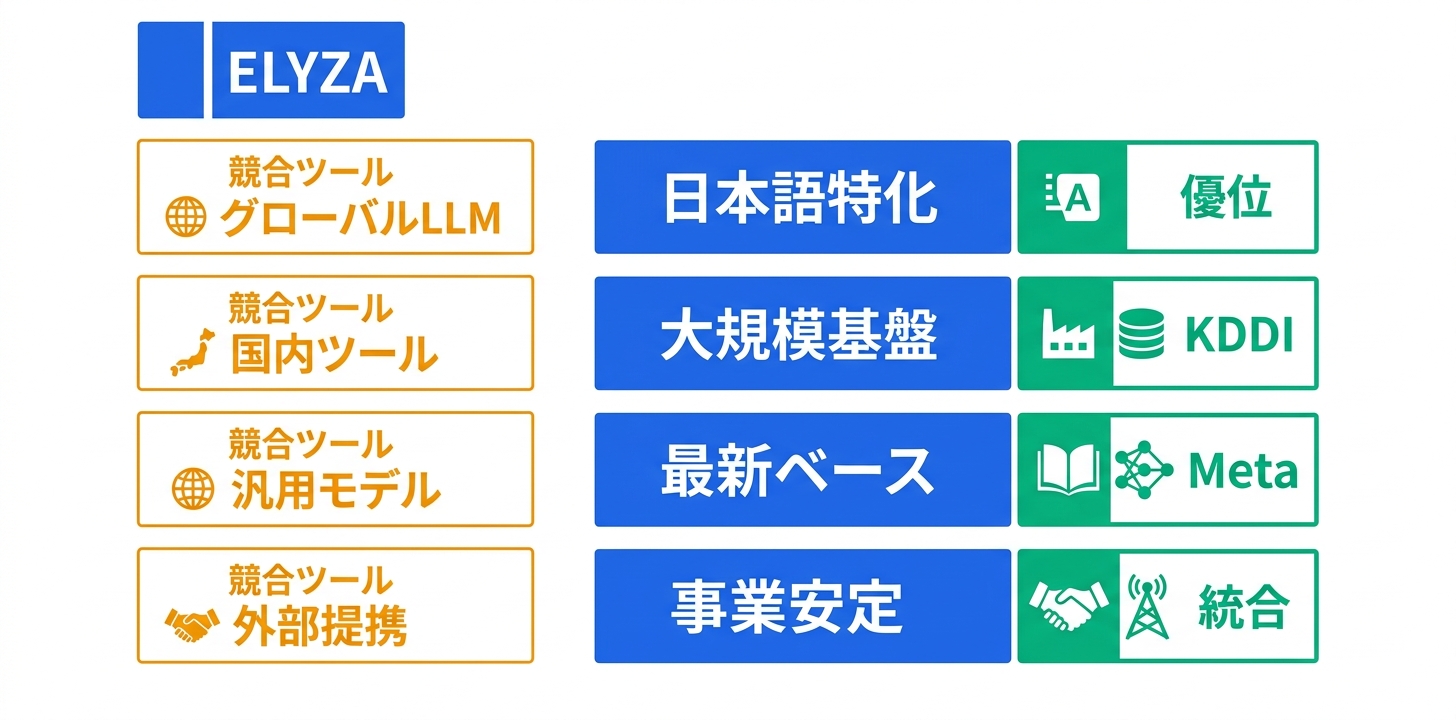
ELYZA LLMの最大の競合は、OpenAI GPT-4o、Anthropic Claude 3.5、Google GeminiなどのグローバルLLMです。これらのモデルは多言語対応で日本語もサポートしていますが、ELYZA LLMは日本語に特化したトレーニングにより、特に敬語表現、ビジネス文書のフォーマット、日本固有の文化的コンテキストの理解において優位性を持ちます。国内の競合としては、NEC cotomi、NTTのtsuzumi、Preferred Networksのplamo、CyberAgent CALM3などが挙げられます。ELYZA LLMの差別化ポイントは、Metaの最新オープンソースモデルをベースにした継続事前学習アプローチにより、グローバルモデルの汎用能力を維持しながら日本語特化の強化を実現している点です。また、KDDIグループ傘下という事業基盤の安定性と、通信インフラとの統合によるエッジAI展開の可能性も他社にない強みです。
📌 技術的な特長と仕組み
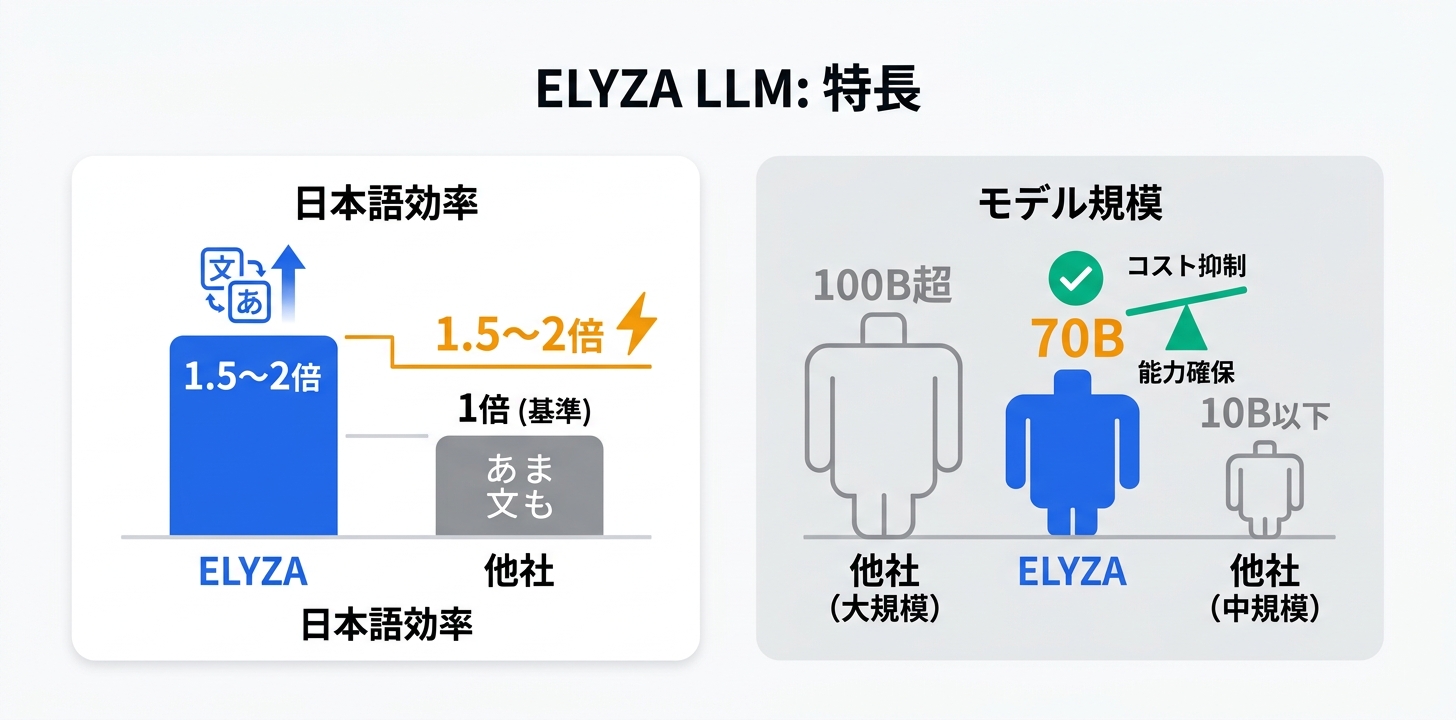
ELYZA LLMの技術的な特長は、Metaが公開するLlama系の大規模言語モデルに対して、日本語テキストコーパスを用いた継続事前学習(Continual Pre-training)を行い、さらにInstruction TuningとRLHF(人間フィードバックによる強化学習)で対話能力を強化するアプローチにあります。2026年公開のELYZA-LLM-Diffusionでは、拡散モデル(Diffusion Model)の手法をテキスト生成に応用するという革新的なアーキテクチャを採用しています。従来の自己回帰型モデル(トークンを左から右に順番に生成)とは異なり、拡散モデルベースのアプローチではテキスト全体を同時に生成・修正するため、長文生成における一貫性の向上と、生成速度の改善が期待されています。モデルサイズは70Bパラメータ(約700億パラメータ)を採用しており、十分な推論能力を確保しながらも、より大規模な100B超のモデルと比較して推論コストを抑制しています。日本語トークナイザーの最適化により、日本語テキストのトークン効率が海外モデルの約1.5〜2倍に向上しており、同じコンテキスト長でより多くの日本語テキストを処理できます。
🚀 導入効果のエビデンスとROI

ELYZA LLMを導入した企業の実績データによると、コールセンターの応対後記録(ACW)作成時間が平均60%削減、法務部門の契約書レビュー時間が40%短縮、マーケティング部門のコンテンツ制作工数が50%削減といった効果が報告されています。金融機関での導入事例では、月間約3,000件の顧客問い合わせメールの自動分類・要約により、オペレーターの処理能力が2倍に向上し、年間約5,000万円のコスト削減を実現しました。投資対効果(ROI)については、PoC期間を含めた初年度で150〜300%のROIが見込まれるケースが多く、特にテキスト処理業務の比重が高い金融・法務・メディア業界での効果が顕著です。導入企業の継続率は95%以上と高く、一度導入した企業のほとんどが利用を拡大していることからも、実務における有用性が裏付けられています。
🚀 始め方ステップバイステップ
ステップ1:デモ版での体験
elyza.ai/lp/elyza-llmにアクセスし、無料デモ版でELYZA LLMの日本語処理能力を体験します。
ステップ2:ユースケースの特定
自社のどの業務にELYZA LLMを適用するか、具体的なユースケースと期待効果を整理します。
ステップ3:お問い合わせ・PoC相談
ELYZAの営業チームに問い合わせ、PoC(概念実証)の実施について相談します。導入前の検証により、効果とフィジビリティを確認します。
ステップ4:PoCの実施
限定的な範囲でELYZA LLMを試験導入し、精度・速度・業務適合性を評価します。
ステップ5:本番導入と運用開始
PoCの結果に基づいて本番環境への導入を進め、API統合やシステム連携を構築して運用を開始します。
🔒 セキュリティとコンプライアンス
ELYZA LLMは、日本国内のデータセンターでモデルを運用しているため、個人情報保護法やマイナンバー法に準拠したデータ処理が可能です。金融機関向けにはFISC安全対策基準への適合、医療機関向けには医療情報システムの安全管理に関するガイドラインへの準拠をサポートしています。オンプレミス環境への導入も可能で、機密性の高いデータを社外に出すことなくLLMを活用できます。また、SOC 2 Type II認証の取得に向けた取り組みも進めており、グローバル基準のセキュリティ認証にも対応予定です。監査ログ機能により、いつ・誰が・どのようなデータを処理したかの追跡が可能であり、金融庁や厚生労働省の監査にも対応できる体制を整えています。KDDIグループのセキュリティポリシーに準拠した運用管理体制が、大企業の情報セキュリティ部門からの信頼獲得に寄与しています。
💡 活用のコツ・裏技
- ▸ELYZA LLMは日本語のコンテキスト理解に優れているため、プロンプトは日本語で具体的に記述するのが最も効果的です。英語での指示は不要です。
- ▸業界固有の専門用語や社内用語をプロンプトに含める場合は、初回使用時に用語の定義を明示すると、以降の応答精度が向上します。
- ▸要約タスクでは、出力の形式(箇条書き、段落形式、表形式等)と要約の長さを明示的に指定すると、期待に沿った出力が得られます。
- ▸ファインチューニングを行う場合は、高品質なトレーニングデータの準備が精度に直結するため、データのクリーニングとキュレーションに十分な時間を投資しましょう。
- ▸オープンソースモデル(ELYZA-LLM-Diffusion)を試す場合は、Hugging Faceからダウンロードし、適切なGPU環境(VRAM 40GB以上推奨)で実行してください。
🎯 向いている人・向いていない人
🎯 向いている人
- ▸日本語テキスト処理の品質を最重視する日本企業のDX推進担当者
- ▸金融・法務・医療など、コンプライアンスとセキュリティ要件が厳しい業界の企業
- ▸データの国内処理を必須とし、海外LLMへのデータ送信を避けたい組織
- ▸日本語特化のカスタムLLMをファインチューニングで構築したい技術チーム
- ▸KDDIグループのエコシステム内でAI活用を推進したい企業
📌 向いていない人
- ▸個人利用で手軽にAIチャットボットを使いたい一般消費者
- ▸英語や多言語でのタスク処理が主な用途の場合
- ▸画像・動画・音声などマルチモーダルAIが必要な場合
- ▸明確な料金表に基づいた予算管理が必要な小規模事業者
- ▸グローバル標準のLLM(GPT-4、Claude)との互換性を重視する場合
📌 今後のロードマップと将来展望
ELYZA LLMは2026年以降、さらなる進化を計画しています。マルチモーダル対応(画像・音声入力の処理)の実装、コンテキストウィンドウの128Kトークンへの拡張、リアルタイムストリーミング推論の高速化が予定されています。KDDIの5Gインフラとの統合により、エッジデバイスでのオンデバイスAI推論の実現も視野に入れています。また、業界特化モデル(金融、医療、法務、製造業向け)の開発・提供も進行中であり、各業界の専門知識をより深く組み込んだ特化型LLMが2026年後半にリリース予定です。
📊 総合評価とまとめ
ELYZA LLMは、日本語処理に特化した国産LLMとして、海外製LLMでは実現困難な高品質な日本語テキスト生成・理解能力を提供するプラットフォームです。金融業界をはじめとする大企業での本番運用実績、日本国内でのデータ処理によるコンプライアンス対応、KDDIグループのバックアップによる事業継続性は、日本企業のAI導入において大きな安心材料です。2026年のELYZA-LLM-Diffusionの公開は、国産LLMの技術力が世界水準に達していることを示す重要なマイルストーンです。一方、個人向けサービスの限定性、料金の不透明さ、マルチモーダル対応の遅れは課題として残ります。日本語品質とデータセキュリティを最優先する企業にとっては、海外製LLMの代替・補完として最も有力な国産AIプラットフォームです。日本語AIの未来を切り拓く存在として、今後の発展にも大いに期待できます。総合評価:4.0/5.0。